Large language models (LLMs) are arguably the most important machine learning (ML) innovation of the past decade. Beyond enabling a number of magical use cases (from generative art to emotional support chatbots), they have flipped the common narrative around machine learning on its head. Ordinarily, ML was thought to be something that automates away mundane tasks and enables humans to focus on things that we do best like creative work, critical thinking and communication. What the latest innovations in LLMs have proven is that in fact ML can be really good, if not better than humans, at these complex, imaginative tasks.
Take the below examples of DALL-E, a LLM from OpenAI that is able to generate realistic pictures and pieces of art from natural language descriptions.

A brief history of LLMs
Before we jump into why we’re so excited about LLMs, we want to provide a brief history of the technology and why now is such an important moment for innovators in the field.
The basic idea of a language model is not new and has in fact been around for decades. Language models at their core perform a simple task: given a string of text, they predict the most likely next word. Over the years, language models have evolved from basic N-gram models (whereby language is represented by simple vectors) to more complex recurrent (RNN) and long short-term memory (LSTM) neural networks, which model words and phrases in more complex architectures.
However, it was the introduction of the transformer architecture from Google Brain’s seminal 2017 paper “Attention Is All You Need” that changed the game for the field of language modeling. While previous language models were based on understanding and processing each word individually, transformers allowed for the processing of sentences and paragraphs as a whole. These models were able to assign different weights to each word in a string based on how it relates to others in the string; words could now be understood contextually, leading to major breakthroughs in performance. In sum, transformers enabled LLMs to have a deep, contextual understand of human intent from natural language, which has enabled a bunch of very exciting use cases: generating art or content from a description, distilling large volumes of unstructured data into a concise summary, more accurate translation, answering complex queries, and more.
Additionally, transformers lend themselves nicely to parallelization, allowing for training on much larger datasets than previously imagined. What researchers at OpenAI and others discovered when training the earliest LLMs like GPT was that discontinuous jumps in performance could be achieved when these models were trained on a massive corpora of heterogeneous data. Today, LLM training involves scraping nearly every piece of text data available on the open web and can cost upwards of $10m. The cloud giants are leveraging supercomputer-sized clusters to train larger and larger models, which are now capable of general language understanding that has never been seen before.
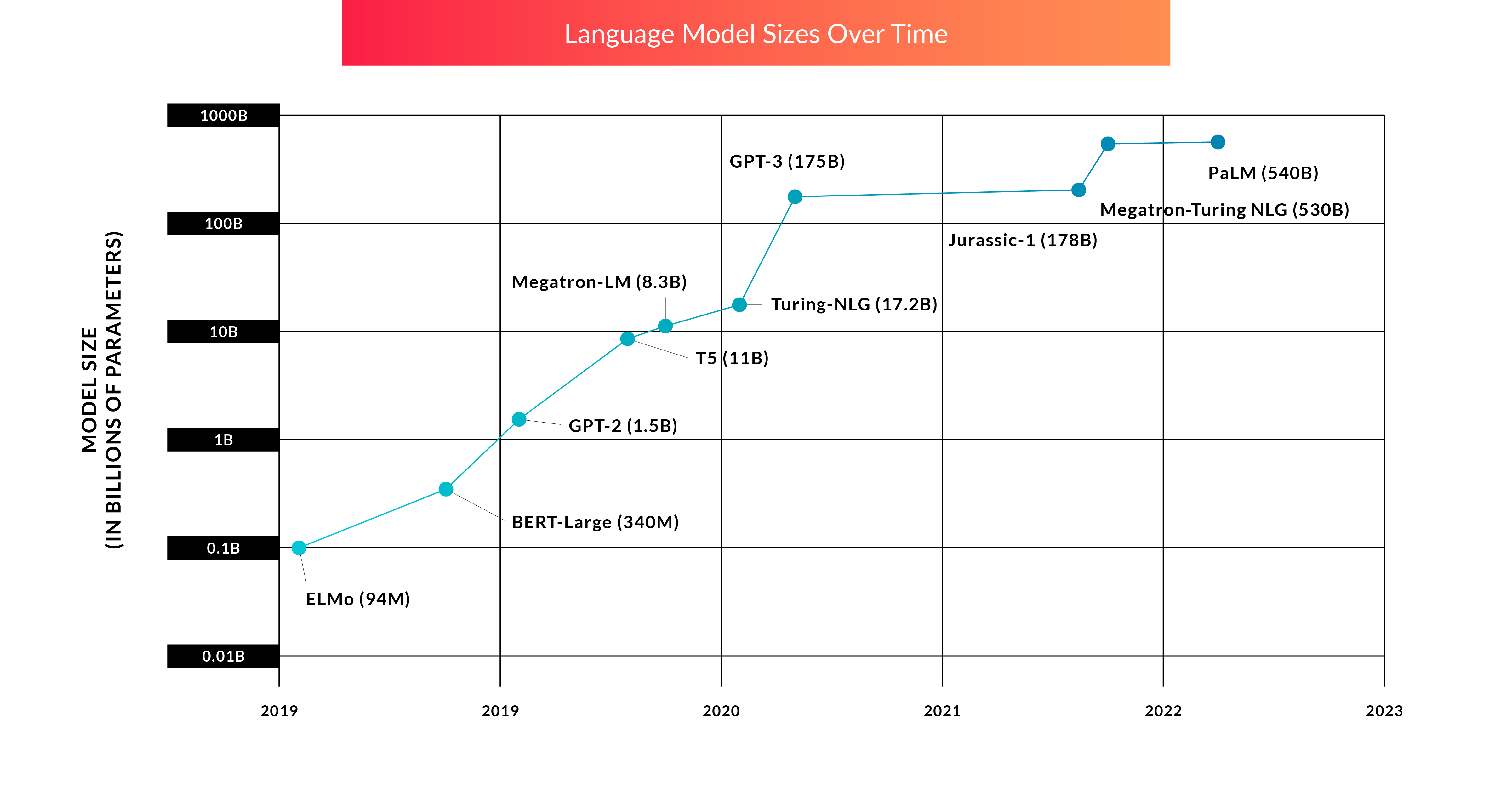
In many ways, the focus on training larger and larger models can be described as an arms race between the large cloud providers. Given the computational and storage intensity involved in LLM training and inference, the cloud providers view owning the core algorithms as the ultimate lead-gen for their infrastructure businesses. By the time you read this, it’s entirely possible a new LLM is trained with exponentially more parameters. Rumor has it that GPT-4 will have 100 trillion – as many parameters as the brain has synapses!
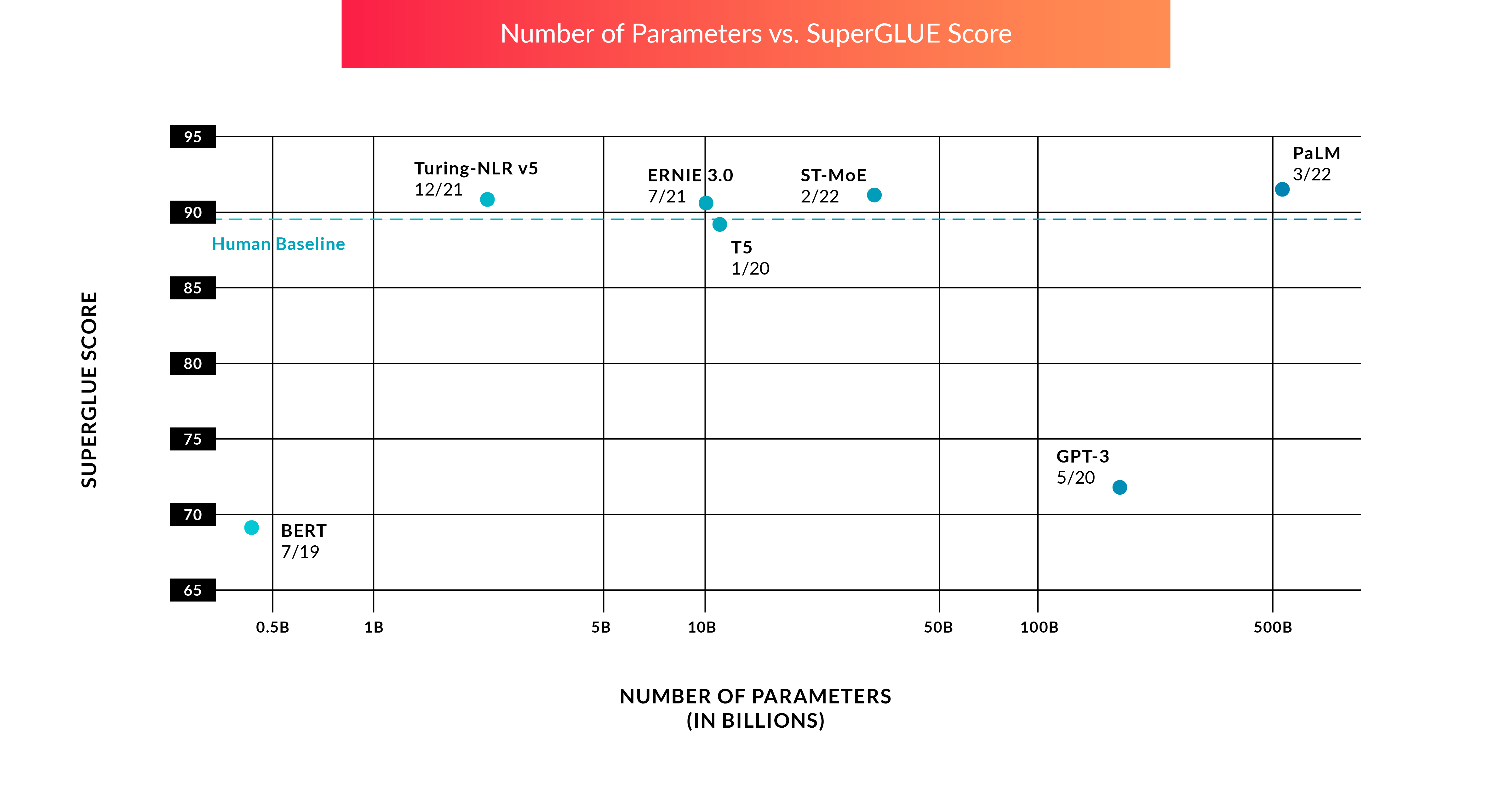
While today, training and inference for LLMs is incredibly expensive, the more promising trend is that models are performing better and better with increasingly fewer parameters. What is noteworthy about this graph is that four of these recent models perform better than the human baseline when it comes to SuperGLUE scores, a popular benchmark for measuring NLP performance from NYU Professor Sam Bowman. SuperGLUE tests these models on a range of natural language tasks including reading comprehension and evaluating gender bias in text.
The Promise
The promise of ML systems has always been about automating mundane tasks and giving humans leverage on their time to do the things humans do best: be creative, have empathy, communicate, and answer complex questions. However, large language models have flipped this script and are showing incredible promise in outsourcing human creativity and critical thinking. From generating realistic art with DALL-E, to answering questions from unstructured data, to providing software engineers with code recommendations, we have seen a range of real-world applications that we believe will generate several enormous opportunities.
Broadly speaking, we divide LLM companies into infrastructure and application layer solutions.

Infrastructure
The infrastructure solutions aim to provide the core algorithms, APIs and tooling for general purpose LLMs. The players in this space include the US Internet giants like Microsoft, Meta, and Google, as well as Chinese companies like Baidu and Tencent. There are also a number of emerging startups in the space such as Cohere and Adept AI, both of which have their roots in Google Brain, the organization that authored the original transformer model.
Application layer solutions
At the application level, we divide startups into the categories of search, generation, and synthesis, though we understand that many of these companies fall into multiple of these buckets. The search companies are focused on using LLMs to better match a user’s keywords or intents with a corpus of unstructured text data. As we all know, search within enterprise software solutions can be horrific, so companies like Hebbia or Dashworks which aim to approach this problem in a much more intelligent way are very exciting.
The generation category refers to companies that are leveraging the creative power of LLMs to produce content that would otherwise require human labor. The most common type of startup we’ve seen in this category is focused on generating marketing copy. While these companies are fascinating and have experienced tremendous growth recently, we have concerns about their defensibility given that marketing copy is publicly available and likely to be scraped by the next general purpose LLM from a big cloud provider. We believe a more interesting company in this space is Tavus, which uses LLMs plus synthetic speech and vision technology to generate custom deepfake videos for sales and marketing use cases. Personalized videos have been shown to increase conversation substantially in b2b sales but generating these manually is painstakingly difficult. Tavus offers a unique approach to automating this high-value task while retaining somewhat of a data moat.
Finally, and one we find incredibly interesting, is the category of synthesis, whereby LLMs are used for both search and generation-like tasks, mining information from multiple sources of unstructured text data, generating unique insights or summaries, and communicating those back in natural language. Synthesis companies are in many ways doing the reverse of generation companies; rather than generating large, unstructured content from a single sentence or paragraph, they distill large volumes of unstructured content into a summary of sorts. These include companies like Viable, which analyzes customer feedback from multiple sources and produces a report to inform product decisions. Another notable example in this category is Zebrium, which analyzes log data and produces a summary on root causes of infrastructure failures.
Of note also are a few businesses that are building consumer experiences in this space, such as Replika and Character AI. We view these consumer, chatbot-esque experiences as falling into both the synthesis and generation categories and are excited to see what they produce.
The Perils
While large language models have a tremendous amount of promise to revolutionize myriad industries, they also pose a number of distinct threats.
First, LLMs have been known to veer off course and say things that are inappropriate, irrevelent, or worse, discriminatory. For this reason, we think LLMs should be unleashed in contexts that make sense, where their power to think creatively and empathetically is valued. This is why LLM startups today are focused on things like generating first drafts of blog posts as opposed to customer support bots, which you don’t want to be sassy or funny, but simply to answer a customer’s requests. We also believe that all startups working in this space need to have a human-in-the-loop to verify content before it touches an end user.
Second, LLMs have been known to plagiarize or make stuff up. In a world of fake news, the last thing we need is models that can generate it en masse without proper checks. To this end, we are very excited about LLM-related companies that are focused on responsibility, explainability, and verification. We need to ensure these algorithms are not black boxes and that their behaviors are well understood and therefore able to be controlled or corrected. Finally, startups need to ensure that content generated by the LLM can always be verified as synthetically generated. Imagine a deepfake spreading – how does one know if it’s real or fake? How can we verify if a piece of art was generated by DALL-E or a human artist? These are critical questions startups commercializing LLMs need to answer before they unleash them into the wild.
The future of LLMs
Overall, we believe the number of possibilities for LLMs are truly endless; the ability to automate and scale human communication and empathy can completely revolutionize fields like mental health and education via affordable, personalized 1-1 therapy or tutoring. The entertainment industry may forever be changed by algorithms that can dynamically create content for each end user’s unique tastes. The list goes on and on.
Overall, there are a few distinct characteristics that excite us about startups innovating with LLMs.
- Enterprise ROI. We have seen LLMs be leveraged for tasks like graphic design or for more complex tasks like incident response in DevOps (like Zebrium). The latter category of business is long-term more exciting – though a much harder model and product to build in the short-term – because the value of the work is much higher ROI and therefore willingness to pay from enterprises will be much higher.
- Humans in the loop. Building on the above point, we love companies that give knowledge workers leverage on their time and allow them to make better decisions or produce better content. Additionally, given the high variability in LLM outputs today, we believe that a pair of human eyes will be necessary for quality assurance purposes.
- Domain specificity. We’re excited about companies leveraging small, domain-specific models as opposed to large, general-purpose ones. We believe this approach will help avoid competition from the cloud providers who have the money and computational resources to build the best general purpose models. Moreover, these types of models will also be cheaper for a startup to build and run given the high cost of LLM training and inference.
- Proprietary data + data moats. We believe that LLMs are not zero-sum and can continually get smarter on new domains without sacrificing performance. This is why copywriting LLM companies are less interesting to us; OpenAI can train their next GPT model on all marketing copy available on the web and performance of their Codex and Github CoPilot functionality won’t deteriorate. On the flip side, companies that collect datasets that are proprietary to each customer will be sitting on a data moat that only grows over time as more customers adopt their product.
We are so excited by LLMs that embrace these characteristics. If you’re an entrepreneur harnessing LLMs to create more useful, exciting, and ethical product experiences, we’d love to hear from you.